Architecting Extensible AI Agents - A Modular Core with Pluggable Skills and SSE Communication

Learn how to architect AI agent systems with a modular, skill-based approach and implement real-time communication using Server-Sent Events (SSE).
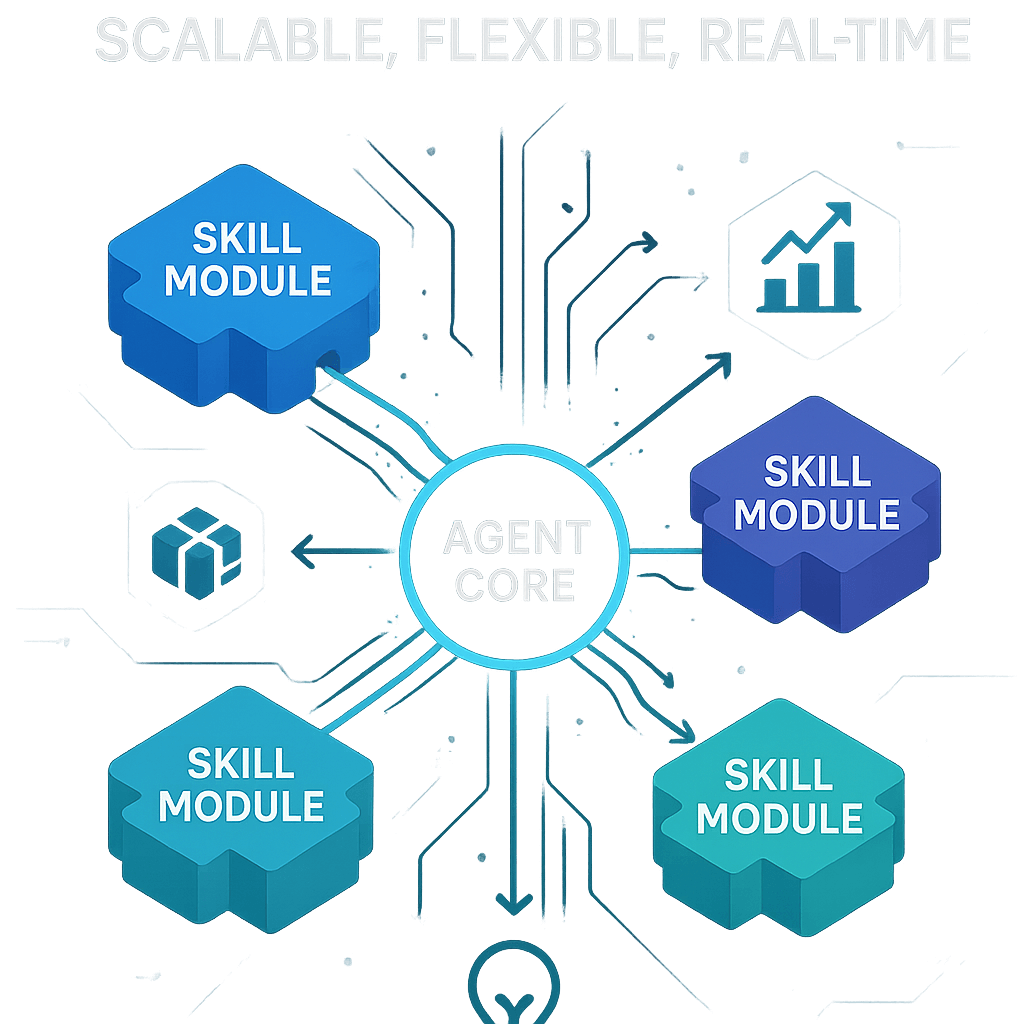
AI agents have become increasingly sophisticated, but their architecture often struggles to scale as complexity increases. Monolithic agent designs, where all capabilities are tightly coupled into a single codebase, become unwieldy as feature requirements expand. In this post, I'll share a modular approach to AI agent architecture that addresses these challenges by separating core orchestration logic from specialized "skills" and implementing efficient real-time communication using Server-Sent Events (SSE).
The Problem with Monolithic Agents
Before diving into the solution, let's understand why traditional monolithic agent designs become problematic:
- Tight Coupling: When all capabilities are intertwined, changes to one feature risk breaking others.
- Poor Scalability: Both technical (codebase complexity) and team (developer coordination) scalability suffer.
- Limited Extensibility: Adding new capabilities often requires modifying core agent code.
- Deployment Challenges: The entire agent must be redeployed for any change, increasing downtime risk.
- Technology Lock-in: Using different technologies for different capabilities becomes difficult.
As we developed more sophisticated AI agents with multiple capabilities, these limitations became increasingly apparent. We needed a better approach.
A Modular, Skill-Based Architecture
The solution is a modular architecture that separates concerns and enables independent development and deployment of agent capabilities. At its core, this architecture has three main components:
- Agent Core: Handles orchestration, state management, and communication.
- Skills: Independent modules that implement specific capabilities.
- Communication Layer: Enables real-time interaction between the core and skills.
Let's look at the implementation of each component:
The Agent Core
The agent core functions as a central hub, responsible for:
- Managing the overall agent state
- Orchestrating skill execution
- Handling user interactions
- Providing a unified API for clients
Here's a simplified implementation of the agent core:
class AgentCore:
def __init__(self):
self.skills = {} # Registered skills
self.state = {} # Agent state
self.session_store = SessionStore() # For persisting sessions
def register_skill(self, skill_name, skill_endpoint):
"""Register a skill with the agent core."""
self.skills[skill_name] = skill_endpoint
logger.info(f"Registered skill: {skill_name} at {skill_endpoint}")
async def execute_skill(self, skill_name, input_data):
"""Execute a specific skill and return results."""
if skill_name not in self.skills:
raise SkillNotFoundError(f"Skill '{skill_name}' not registered")
skill_endpoint = self.skills[skill_name]
# Create SSE client to receive real-time updates
async with SSEClient(f"{skill_endpoint}/execute") as client:
# Send initial request
await client.send_request(input_data)
# Process SSE events
async for event in client:
event_data = json.loads(event.data)
event_type = event.event or "update"
# Handle different event types
if event_type == "status":
self.state["status"] = event_data["status"]
yield {"type": "status", "data": event_data}
elif event_type == "thinking":
yield {"type": "thinking", "data": event_data["content"]}
elif event_type == "result":
self.state["last_result"] = event_data
yield {"type": "result", "data": event_data}
elif event_type == "error":
yield {"type": "error", "data": event_data["message"]}
async def process_request(self, user_request):
"""Process a user request, determining which skill to use."""
# Determine appropriate skill based on request
skill_name = self.determine_skill(user_request)
# Execute the skill and stream results
async for update in self.execute_skill(skill_name, user_request):
yield update
def determine_skill(self, request):
"""Determine which skill should handle a request."""
# This could use LLM-based routing, rule-based matching, etc.
# Simplified implementation for demonstration
if "translate" in request.get("action", "").lower():
return "translation"
elif "ground" in request.get("action", "").lower():
return "grounding"
else:
return "default"
Skills as Independent Services
Skills are implemented as standalone services with their own API endpoints. Each skill:
- Has a well-defined interface for communication with the core
- Manages its own dependencies and resources
- Can be developed, tested, and deployed independently
- Exposes an SSE endpoint for real-time updates
Here's an example of a grounding skill that helps validate inputs against reliable sources:
class GroundingSkill:
def __init__(self):
self.llm_client = LLMClient() # LLM service client
self.search_client = SearchClient() # Web search client
async def ground(self, statement, search_results=None):
"""Ground a statement using search results or by performing a search."""
# Get search results if not provided
if not search_results:
search_results = await self.search_client.search(statement)
# Use LLM to evaluate statement against search results
evaluation = await self.llm_client.evaluate_grounding(
statement=statement,
sources=search_results
)
return {
"statement": statement,
"is_grounded": evaluation["is_grounded"],
"confidence": evaluation["confidence"],
"sources": evaluation["relevant_sources"],
"reasoning": evaluation["reasoning"]
}
async def process_grounding_request(self, request, sse_response):
"""Process a grounding request with SSE updates."""
statement = request.get("statement", "")
# Send status update
await sse_response.send(
data=json.dumps({"status": "Searching for relevant information"}),
event="status"
)
# Perform search
search_results = await self.search_client.search(statement)
# Send thinking update
await sse_response.send(
data=json.dumps({"content": "Analyzing search results for relevant information"}),
event="thinking"
)
# Ground the statement
result = await self.ground(statement, search_results)
# Send final result
await sse_response.send(
data=json.dumps(result),
event="result"
)
This skill can be deployed as a separate microservice with FastAPI:
from fastapi import FastAPI, Request
from sse_starlette.sse import EventSourceResponse
app = FastAPI()
grounding_skill = GroundingSkill()
@app.post("/execute")
async def execute_skill(request: Request):
"""Execute the grounding skill with SSE updates."""
request_data = await request.json()
async def event_generator():
try:
await grounding_skill.process_grounding_request(request_data, SSEResponse())
except Exception as e:
# Send error event
await SSEResponse().send(
data=json.dumps({"message": str(e)}),
event="error"
)
return EventSourceResponse(event_generator())
class SSEResponse:
"""Helper class to send SSE events."""
async def send(self, data, event=None):
if event:
return {"event": event, "data": data}
return {"data": data}
SSE for Real-Time Communication
A critical aspect of this architecture is the real-time communication between the agent core and skills. We chose Server-Sent Events (SSE) over alternatives like WebSockets for several reasons:
- Simplicity: SSE is simpler to implement than WebSockets, especially for one-way communication.
- HTTP-Based: SSE works over standard HTTP, making it easier to deploy and debug.
- Automatic Reconnection: Browsers handle reconnection for SSE automatically.
- Message Types: SSE supports named events, which helps organize different update types.
Our implementation includes custom SSE classes for both client and server sides:
class SSEClient:
"""Client for connecting to SSE endpoints and sending initial requests."""
def __init__(self, url):
self.url = url
self.session = None
self.response = None
async def __aenter__(self):
self.session = aiohttp.ClientSession()
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
if self.session:
await self.session.close()
async def send_request(self, data):
"""Send initial request to the SSE endpoint."""
headers = {
"Content-Type": "application/json",
"Accept": "text/event-stream"
}
self.response = await self.session.post(
self.url,
json=data,
headers=headers
)
async def __aiter__(self):
"""Iterate through SSE events."""
if not self.response:
return
# Process the SSE stream
buffer = ""
async for line in self.response.content:
line = line.decode('utf-8')
buffer += line
if buffer.endswith('\n\n'):
event = self._parse_event(buffer.strip())
if event:
yield event
buffer = ""
def _parse_event(self, data):
"""Parse an SSE event from string data."""
if not data:
return None
lines = data.split('\n')
event_data = {}
for line in lines:
if line.startswith('data:'):
event_data['data'] = line[5:].strip()
elif line.startswith('event:'):
event_data['event'] = line[6:].strip()
elif line.startswith('id:'):
event_data['id'] = line[3:].strip()
return event_data if 'data' in event_data else None
The Translation Skill: A Case Study
Let's look at a complete example of another skill implementation - the translation skill:
class TranslationSkill:
"""Skill for translating text between languages."""
def __init__(self):
self.llm_client = LLMClient()
self.supported_languages = self._load_supported_languages()
def _load_supported_languages(self):
"""Load supported language codes and names."""
# In practice, this would load from a configuration file
return {
"en": "English",
"es": "Spanish",
"fr": "French",
"de": "German",
"zh": "Chinese",
"ja": "Japanese",
# ... more languages
}
async def translate(self, text, source_lang, target_lang):
"""Translate text from source language to target language."""
# Validate languages
if source_lang not in self.supported_languages:
raise ValueError(f"Unsupported source language: {source_lang}")
if target_lang not in self.supported_languages:
raise ValueError(f"Unsupported target language: {target_lang}")
# Use LLM for translation
prompt = f"""
Translate the following text from {self.supported_languages[source_lang]} to {self.supported_languages[target_lang]}:
{text}
Provide only the translated text without any additional explanation.
"""
response = await self.llm_client.generate(prompt)
return {
"original_text": text,
"translated_text": response.strip(),
"source_language": source_lang,
"target_language": target_lang
}
async def process_translation_request(self, request, sse_response):
"""Process a translation request with SSE updates."""
text = request.get("text", "")
source_lang = request.get("source_lang", "auto")
target_lang = request.get("target_lang", "en")
# If source language is auto, detect it
if source_lang == "auto":
await sse_response.send(
data=json.dumps({"status": "Detecting language"}),
event="status"
)
source_lang = await self._detect_language(text)
# Send status update
await sse_response.send(
data=json.dumps({
"status": f"Translating from {self.supported_languages.get(source_lang, source_lang)} to {self.supported_languages.get(target_lang, target_lang)}"
}),
event="status"
)
# Send thinking update
await sse_response.send(
data=json.dumps({
"content": "Processing translation request..."
}),
event="thinking"
)
# Perform translation
result = await self.translate(text, source_lang, target_lang)
# Send final result
await sse_response.send(
data=json.dumps(result),
event="result"
)
async def _detect_language(self, text):
"""Detect the language of the input text."""
prompt = f"""
Identify the language of the following text. Respond with only the ISO 639-1
language code (e.g., 'en' for English, 'es' for Spanish):
{text}
"""
response = await self.llm_client.generate(prompt)
detected_lang = response.strip().lower()
# Default to English if detection fails
if detected_lang not in self.supported_languages:
return "en"
return detected_lang
Integration with MCP Protocol
For our implementation, we integrated the skills with the MCP (Model Control Protocol) for consistent message formatting and handling. MCP provides a standardized way for models and agents to communicate with clients:
class MCPHandler:
"""Handles MCP protocol formatting for SSE events."""
@staticmethod
def format_thinking(thinking_text):
"""Format thinking update in MCP format."""
return {
"type": "thinking",
"content": thinking_text,
"timestamp": datetime.now().isoformat()
}
@staticmethod
def format_status(status_text):
"""Format status update in MCP format."""
return {
"type": "status",
"status": status_text,
"timestamp": datetime.now().isoformat()
}
@staticmethod
def format_result(result_data):
"""Format final result in MCP format."""
return {
"type": "result",
"content": result_data,
"timestamp": datetime.now().isoformat()
}
@staticmethod
def format_error(error_message):
"""Format error in MCP format."""
return {
"type": "error",
"message": error_message,
"timestamp": datetime.now().isoformat()
}
Client Implementation
Clients can connect to the agent core and receive real-time updates through SSE:
// Client-side JavaScript for connecting to the agent
const connectToAgent = async (request) => {
const response = await fetch('/api/agent/process', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'text/event-stream'
},
body: JSON.stringify(request)
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
// Process the SSE stream
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const events = chunk.split('\n\n').filter(Boolean);
for (const eventText of events) {
const eventData = parseSSEEvent(eventText);
switch (eventData.type) {
case 'status':
updateStatus(eventData.data.status);
break;
case 'thinking':
updateThinking(eventData.data.content);
break;
case 'result':
displayResult(eventData.data);
break;
case 'error':
showError(eventData.data.message);
break;
}
}
}
};
const parseSSEEvent = (eventText) => {
const lines = eventText.split('\n');
const eventData = {};
for (const line of lines) {
if (line.startsWith('event: ')) {
eventData.type = line.substring(7);
} else if (line.startsWith('data: ')) {
eventData.data = JSON.parse(line.substring(6));
}
}
return eventData;
};
Deployment and Scaling
This modular architecture simplifies deployment and scaling. Each component can be deployed independently:
# Example docker-compose.yml for deploying the system
version: '3'
services:
agent-core:
build: ./agent-core
ports:
- "8080:8080"
environment:
- GROUNDING_SKILL_URL=http://grounding-skill:8081
- TRANSLATION_SKILL_URL=http://translation-skill:8082
depends_on:
- grounding-skill
- translation-skill
networks:
- agent-network
grounding-skill:
build: ./grounding-skill
ports:
- "8081:8081"
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY}
networks:
- agent-network
translation-skill:
build: ./translation-skill
ports:
- "8082:8082"
environment:
- OPENAI_API_KEY=${OPENAI_API_KEY}
networks:
- agent-network
networks:
agent-network:
driver: bridge
For Kubernetes deployment, we use Helm charts to manage the deployment of each component:
# Simplified Helm values.yaml example
replicaCount:
agentCore: 2
groundingSkill: 3
translationSkill: 3
images:
repository:
agentCore: agent-core
groundingSkill: grounding-skill
translationSkill: translation-skill
tag: latest
pullPolicy: Always
service:
type: ClusterIP
port: 80
Benefits of this Architecture
This modular architecture with SSE communication provides numerous benefits:
- Independent Development: Teams can work on different skills without affecting each other.
- Flexible Scaling: Each skill can be scaled independently based on usage patterns.
- Technology Flexibility: Different skills can use different technologies or languages as needed.
- Incremental Deployment: New skills can be added without redeploying the entire system.
- Enhanced Resilience: Failures in one skill don't affect the entire system.
- Real-Time Updates: SSE provides efficient streaming of updates to clients.
- Simplified Testing: Skills can be tested in isolation with mock dependencies.
Challenges and Considerations
While this architecture offers significant advantages, there are challenges to consider:
1. Increased Operational Complexity
Managing multiple services instead of a monolith increases operational complexity. We addressed this with:
- Comprehensive monitoring and logging
- Automated deployment pipelines
- Service discovery mechanisms
- Centralized configuration management
2. Consistency Across Skills
Ensuring consistent behavior across independently developed skills requires:
- Clear interface definitions
- Shared utilities for common functions
- Style guides and code standards
- Regular cross-team reviews
3. Error Handling
Distributed systems need robust error handling:
# Example of error handling in the agent core
async def execute_skill_with_fallback(self, primary_skill, fallback_skill, input_data):
"""Execute a skill with fallback if it fails."""
try:
async for update in self.execute_skill(primary_skill, input_data):
yield update
except SkillExecutionError as e:
logger.error(f"Primary skill {primary_skill} failed: {str(e)}")
logger.info(f"Falling back to {fallback_skill}")
# Notify the client of the fallback
yield {
"type": "status",
"data": {"status": f"Falling back to alternative approach"}
}
# Execute fallback skill
async for update in self.execute_skill(fallback_skill, input_data):
yield update
4. State Management
Handling state across distributed components requires careful design:
class SharedStateManager:
"""Manages shared state across skills."""
def __init__(self, redis_url):
self.redis = aioredis.from_url(redis_url)
async def set_state(self, session_id, key, value, ttl=3600):
"""Set a state value with expiration."""
state_key = f"session:{session_id}:{key}"
await self.redis.set(state_key, json.dumps(value), ex=ttl)
async def get_state(self, session_id, key):
"""Get a state value."""
state_key = f"session:{session_id}:{key}"
value = await self.redis.get(state_key)
return json.loads(value) if value else None
Performance and Monitoring
With distributed components communicating via SSE, monitoring performance becomes crucial:
# Example monitoring middleware for FastAPI
@app.middleware("http")
async def add_performance_monitoring(request, call_next):
start_time = time.time()
# Track request by type
metrics.increment(f"requests.{request.url.path}")
# Execute the request
response = await call_next(request)
# Record duration
duration = time.time() - start_time
metrics.timing(f"request_duration.{request.url.path}", duration)
# Track response codes
metrics.increment(f"responses.{response.status_code}")
return response
Conclusion
The modular AI agent architecture with pluggable skills and SSE communication provides a scalable, flexible approach to building complex AI systems. By separating the core orchestration logic from specialized capabilities, we've created a system that can evolve more gracefully over time.
This architecture has enabled us to:
- Scale development across multiple teams
- Add new capabilities without disrupting existing ones
- Provide real-time feedback to users during processing
- Deploy and scale components independently
- Choose the right technologies for each specific skill
While it introduces some additional complexity in terms of deployment and communication, the benefits far outweigh the costs for sophisticated AI agent systems with diverse capabilities.
The combination of a strong orchestration core, independently deployable skills, and efficient SSE communication creates a foundation that can support increasingly advanced AI applications as they evolve.
For teams building complex AI agents, we strongly recommend considering this modular, skill-based approach with real-time communication to create systems that can grow and adapt to changing requirements.