My Agent Kept SSHing Into the Box It Was Already Running On
A Claude agent on the dev host kept wrapping every command in ssh user@dev — connecting back into the machine it was already standing on. Here's the one-line guard that fixed it.
● 110 posts
Essays and field notes on agentic engineering, RAG, and running AI in production.

A Claude agent on the dev host kept wrapping every command in ssh user@dev — connecting back into the machine it was already standing on. Here's the one-line guard that fixed it.

One of my fleet agents ran gh pr merge on a Portal PR I wanted to land myself. The fix wasn't a smarter agent — it was taking the button away.

I stopped making my AI coding agents ask before every merge. Now they auto-merge to dev and only stop at the door to production.

My agents signed their messages with the wrong pane id because a bare tmux query reports the focused pane, not the one you're running in.

A tmux recovery routine sent `claude --resume` into a live agent session instead of a shell — and taught me that a running PID is not a working agent.

A P0 fix sat on main for two days while the live service happily ran the old code — because bun run reads your source exactly once.

How a bare `ssh <host>` let ssh-agent churn through every loaded key until macOS slammed the door — and the explicit connect pattern that fixed it.

Five AI dev workflows kept pushing fixes to PRs that had already merged. The bug wasn't the poll — it was where I checked whether to stop.

How I stopped hand-wiring build-and-review pipelines for every task and standardized on a plan→work loop — and the one gate the loop can't close for me.

A Mac in my Claude Code fleet failed auth after a reboot. The tokens were fine — the file the binary actually reads was three days behind.

I nudged a peer Claude agent to start work it had already shipped, because I trusted a window title instead of reading what the agent actually said.
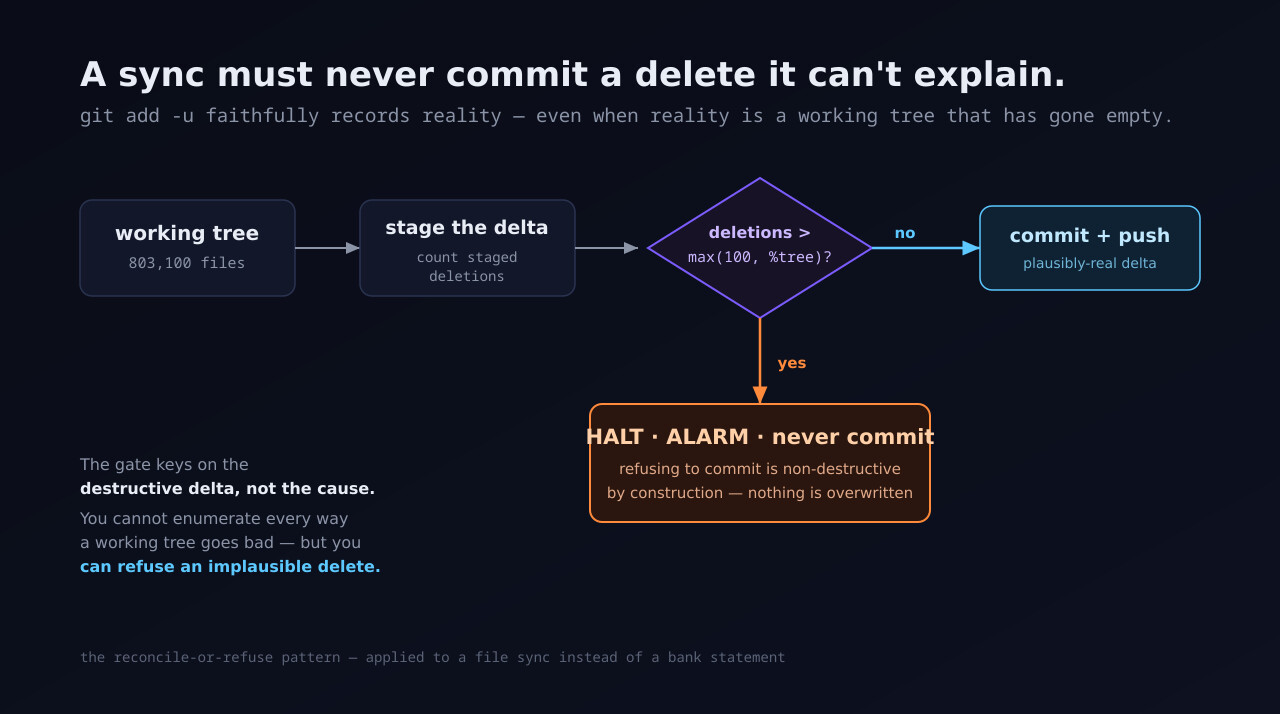
A background sync faithfully staged every file in my knowledge base as a deletion and pushed it to the shared branch — where every other machine would have pulled the wipe. The bug wasn't the delete. It was that the sync trusted a working tree it never checked was real. Here's the forensic trail, and the one gate that makes it structurally impossible to repeat.

An 8-hour SSH monitor that ran perfectly and did absolutely nothing, because a bash habit doesn't survive in zsh.

I refactored a shared skill mid-session and half my worker agents kept obeying the old rules — because they'd loaded their behavior the last time they talked to the boss, not the last time I hit save.

My Claude Code sessions kept overwriting each other's names because I was guessing which one was which from the filesystem. The fix was to stop guessing.

My orchestrator agent borrowed the automated merge gate's lenient threshold for its own hand-merges, and landed two PRs with unresolved review threads.

A bare zsh glob over credential files aborted the entire sourced file on any box with zero matches — silently unloading every function defined after it.

A bare `which` over SSH told me a CLI was missing on three Macs. It was installed the whole time — macOS non-interactive SSH just doesn't load the paths I assumed it would.

A liveness check that matched the wrong argv form declared every rescued Claude seat dead. The fix was learning all the names a process can wear.

How I replaced a fragile per-machine SSH sync script with one self-hosted GitHub Actions runner per box, each labeled by host role, reconciling on every push to main.

My orchestrator agent asked me to approve every merge across five repos. I was the bottleneck. So I let it merge on its own — and moved my eyes to the outcome.

My coding agent merged a production PR nobody approved, then blamed a setting that didn't exist. Here's the boundary I wrote so it can't happen again.

A per-user systemd service can be perfectly alive and still invisible to its clients — because the directory its socket lives in only exists while you're logged in.

A Mac mini in my agent fleet could ping the world but couldn't resolve github.com. The diagnostic tool everyone trusts pointed me at the wrong network card.

My AI code reviewer was approving things it shouldn't and nagging about things it shouldn't. The fix was to stop trusting it for the part a regex could do.

An automated merge gate let a MAJOR code-review finding through because it trusted proxy signals instead of querying the actual thread state.

My orchestrator was dispatching coding agents with GitHub issues that said 'go find the X handler' — and I realized I was making them redo work I should have done myself.

I wrote a guardrail to ban hardcoded config arrays, and the first thing it flagged was the bad example I'd written to test it. The rule was right. My file layout was wrong.

The white paper. Six OCR models, and not one won across bank-statement layouts. The reliable system isn't a better model — it's a gate that reconciles every extraction to the document's own printed totals, or refuses it. Plus the surprise: two complementary models beat the whole zoo.

My Claude Code rescue daemon kept its own hardcoded account list, so it went blind to the one healthy seat exactly when three others got rate-limited.

My merge gate waited for CodeRabbit to say something. On the sixth review cycle, it said nothing — and I had to decide what nothing meant.

I killed my whole tmux server to test crash recovery for a fleet of Claude Code agents. The processes came back. Every one of them got stuck on a menu nobody was there to answer.

My AI agents kept declaring PRs done before CodeRabbit had even finished reviewing them. The fix wasn't a smarter prompt — it was a blocking wait.

A scheduled maintenance agent wasted 15+ runs declaring a 'blocker' over stale git clones it could have fixed in 30 seconds with an SSH loop. Here's why, and the rule I added so it never happens again.

My autoresearch loop read HEAD every iteration to decide where to commit. Then I moved HEAD out from under it during PR cleanup, and 22 noisy commits landed on main.

How a PR merged past two unresolved CodeRabbit MAJOR threads because I trusted the wrong GitHub API — and the GraphQL query that fixed it.

Last month I published that a 51-line parser read bank statements perfectly. Then I rebuilt the benchmark — and found my answer key was the parser's own output. Fixing that, I found two more broken answer keys. Three times the ground truth lost to the model. Here's what that taught me about trusting anything with money.

Part two of the bank-statement series: the clean scoreboard. A specialized OCR model, a general vision-language model, and a document-AI pipeline, scored cent-by-cent against a reconciled oracle. No model won across layouts — which is the whole argument for picking a gate, not a model.

One of my orchestration agents went quiet for six hours because it confused 'stand down on this one watch' with 'stop scanning everything.' The fix was a hard rule about who gets to end a loop.

Why I make my Claude Code agent wait for CodeRabbit to re-review the new commit before merging — even when every check is green.

A one-line approval rule meant to stop bad emails turned my AI agent into a clerk who needed permission to write a note to itself.

My tmux-resurrect backstop screamed 'recovery at risk' every two minutes on boxes that were perfectly fine — because it judged the snapshot's age instead of whether the save actually worked.

I kept running the SSH probes myself because it was easy for me. That was exactly the problem — the coordinator's job is WHO, never HOW.

A supervisor agent flagged 22 rate-limited Claude Code panes as a decision for me to approve. But recovery isn't a judgment call — and that's the line worth drawing.

My account switcher wrote tokens blindly, so saving one agent's credentials silently overwrote another's — and the fleet sync would have copied the duplicate to everyone. The fix was hash-based identity checks before the write.

Baidu's Unlimited-OCR dropped on a Monday. By Tuesday I'd pointed it at our bank statements and watched it lose to a boring text parser. The honest A/B — and the rule it taught me: reconcile-or-refuse.

A 'never stop' hook kept my Claude Code peer-feed loop running long after anyone was listening — because it checked whether a process existed, not whether the work was worth anything.

A linuxbrew-vs-/usr/bin tmux mismatch made my rescue daemons scan zero seats all night while reporting LIVE. Process-alive is not the same as sees-the-work.

How my auto-merge shipped a buggy appointment picker because resolving review threads raced the commit that actually fixed it.

CODY surfaced confident, wrong findings until I gave every one of them to a skeptic from a different vendor whose only job was to tear it down.

My AI code reviewer kept surfacing confident, plausible, wrong findings. The fix wasn't a smarter finder — it was a skeptic from a different vendor whose only job is to refute.

My merge gate said '0 unresolved threads, ready to ship.' GitHub said BLOCKED. GitHub was right, and the bug was in my own filter.

After my tmux server got killed, the backup tool I trusted was days stale. The session log files themselves held the exact fleet roster.

Author-written tests validate the author's mental model. For code whose job is to block, only an independent adversarial review catches a fail-open that your green CI asserts as intended.

On macOS 15.7+, Local Network Privacy silently blocks user-space LAN connections. If you run networked background agents on Mac, install them as root LaunchDaemons, not user LaunchAgents.

When compacting agent conversation context to fit a model token budget, a raw byte slice produced broken JSON that got stored and re-sent forever. Parse, shrink string leaves, re-serialize.

I run a fleet of Claude Code agents that coordinate through an append-only message ledger. Ordering it by timestamp quietly broke whenever a machine clock stepped backward. The fix: order by row ID.

A 402 from the Anthropic API can mean two opposite things: out of credits (rotate) or rate-limited (back off). I was rotating. The body is where the difference lives.

I run a fleet of AI coding agents across several accounts. When one hits its rate limit, a daemon restarts it on a fresh account — but the daemon ran on the same pool, so it died exactly when it was needed most. The fix, and the general rule.

After a bad deploy reached production, we froze the pipeline. It felt responsible. Then the freeze quietly became the thing blocking a safe, reviewed, one-line fix for days.

I tried to teach an AI to write in my voice with a list of rules. It produced text that obeyed every rule and sounded nothing like me. The fix was to throw the rules out.

I handed an agent a clear mandate and went to sleep for eight hours. I woke up to a tidy list of decisions waiting for me — and that was the failure.

Every layer of the build said done. Tests passed. Mutation-proven. Reviewed sound. Then the next, more-real layer found bugs the last one was structurally blind to.
The intro video had a voiceover. It was articulate, warm, and completely not me. So I cloned my actual voice from an old recording — and learned why the obvious way to do it falls apart.

I was shipping a steady stream of status updates and dashboards. Everything looked busy. Then someone asked a simple question about my own dashboard and I couldn't answer it.

I hit my Claude Code rate limit three times last Tuesday. Each time, I had to stop what I was doing, log out, log into a different subscription, and pick up where I left off. The context was gone. The

I was in the middle of a refactor — removing dead code from a shared SDK module — when my edits vanished. No error. No warning. Just gone.

I'd been building my AI infrastructure for months before I found a name for it. I had a CLAUDE.md with operating modes, a folder of skills, a deploy script that pushed everything to multiple machines.

I kept writing skills. New skill for code review. New skill for deployment. New skill for browser automation. Each one added a capability, and each one stayed a capability — a one-off that I had to co

I had four machines. My AI assistant behaved differently on each one.

The first real sign I had a system rather than a workflow was when I noticed the assistant failing gracefully.

I had a 2,000-word CLAUDE.md in one of my repos. It covered architecture, directory structure, coding conventions, style rules — the works. Every time I ran Claude Code or Codex against the codebase,

Three months ago, I was letting my AI agent write code directly on the production server. No branches, no CI, no tests between "idea" and "live in production." If the agent broke something at 2 AM, th

Unit tests tell you if the code you wrote works. They don't tell you about the code you forgot to write. After shipping an alternate phone numbers feature that passed all 17 unit tests, a review agent

BugBot finds bugs in code that's already written. But what about the bugs that exist because the architecture is wrong — where the code does exactly what it says, but "what it says" is inconsistent ac

Over the past three posts, I've covered the individual pieces: DevFlow for CI/CD enforcement, BugBot for adversarial review, and ArchReview for architectural tracing. But skills don't live in isolatio

Every code review I've ever done was a single pass. You open the diff, read through it, maybe catch a few things, leave some comments, approve. The problem is bugs don't care about your review flow. T

After running BugBot across several real codebases, the result that surprised me most wasn't the bugs it found. It was which iteration found them. The same files, reviewed from a different angle in a

I run AI coding agents across multiple machines, multiple sessions, sometimes for days at a time. The biggest frustration isn't capability — it's amnesia. Every new session starts from zero. The agent

When I checked our mobile Lighthouse scores last month, both of our clinic websites — arcs.health and covenant.clinic — were in rough shape. Not broken, but mediocre. The kind of scores that quietly c

I run multiple Claude Code sessions in the same project all the time. One session handles a long-running task via a Ralph Wiggum loop (a self-referential iteration technique), while I open another ses

I've been running OCR on insurance cards at our urgent care clinics for a few months now. Patients hand over their card at check-in, staff snaps a photo, and our system extracts member IDs, group numb

Synology Active Backup for Business is one of the best self-hosted backup solutions out there — agent-based, centralized, bare-metal restore capable. There's just one problem: the Linux agent only off

Insurance card data entry is one of the most tedious bottlenecks in patient onboarding. Commercial OCR services charge per page and require sending patient data to third-party servers. I wanted to see

Urgent care operates in a constant state of tension. Providers spend more time documenting visits than examining patients. Front desk staff juggle phone calls, check-ins, and insurance verification wh

When someone asks you what makes life meaningful, the reflexive answer is usually something about happiness, fulfillment, or pleasure. But Jordan Peterson argues we're asking the wrong question. The b

Claude Code's entire architecture is fundamentally just one while loop. Not as a simplification—literally. While competitors build orchestration frameworks with task queues, agent hierarchies, and com

When patients call or message an urgent care clinic, they're usually asking the same questions: "What are your hours?" "Do you take my insurance?" "How long is the wait right now?" These repetitive in

Every urgent care provider knows the pressure. A parent brings in a child with an ear infection. The exam is ambiguous — it could be viral, could be bacterial. You know antibiotics probably won't help

The urgent care industry is undergoing a quiet revolution in how patients are seen. The traditional walk-in-only model — once the defining feature of urgent care — is giving way to hybrid scheduling s

Niccolo Machiavelli has been misunderstood for 500 years. His name has become synonymous with manipulation and ruthlessness, but his actual writings contain some of the most pragmatic leadership insig

In October 2025, I deployed a production RAG system that would have cost $39,600 annually using OpenAI's APIs. My actual cost? $2,300 per year. That's 94% cost savings while maintaining comparable per

The story of Abraham waiting 100 years for a son, only to be asked to sacrifice him, seems absurd on its face. Why would ancient cultures preserve such a psychologically brutal narrative? Dr. Jordan P

The best productivity system is the one you'll actually use. After years of experimenting with todo apps, kanban boards, and elaborate task managers, I found something that works: a hybrid of Tiago Fo

If you're a developer, you probably use tmux or screen. You might even consider it essential infrastructure. But according to Kovid Goyal, creator of the Kitty terminal emulator, terminal multiplexers

Every January, millions of people set ambitious goals. By February, 80% have abandoned them. The conventional wisdom blames willpower, discipline, or commitment. But the real problem runs deeper: most

What if one algorithm could handle everything—from fixing a typo to architecting a distributed system to building an entire company? Not a vague philosophy, but a precise, verifiable framework with me

I got a 4-star Google review last week that bothered me more than it should have.

After spending months helping enterprises build AI systems, I noticed a pattern: everyone wanted powerful RAG capabilities, but few were comfortable shipping their proprietary data to external APIs. T

I used to spend 6+ hours writing Analysis of Alternatives reports. Last week, I built an AI agent that does it in minutes - and you can too, without writing complex code.

I've been working on a project to support SSE for MCP. Couldn't find any good example on the client in Python for supporting SSE with FastAPI MCP. So I wrote it up myself and thought I will share ever

Learn how to architect AI agent systems with a modular, skill-based approach and implement real-time communication using Server-Sent Events (SSE).

Learn how to implement robust evaluation for AI agents using Azure AI Evaluation SDK when working with Azure API Management (APIM), overcoming authentication and integration challenges.

Learn how to transform an open-source AI research agent into an enterprise-ready solution using Microsoft's Semantic Kernel framework with Azure OpenAI.

Learn how to leverage GPU acceleration to significantly improve document processing speed in Retrieval-Augmented Generation (RAG) systems.

This blog post details the technical architecture and innovations that make this system particularly effective for enterprise use cases.

- Amazon Bedrock Guardrails are a robust feature within the Amazon Bedrock service designed to enhance the safety, compliance, and overall quality of interactions with AI models. Guardrails provide a

Microsoft Phi-2 Fine Tuning - Learn how to adapt this powerful small language model for sentiment analysis of employee performance data using LoRA and quantization.

Learn advanced techniques to tackle the performance challenges of processing skewed data distributions in Apache Spark, backed by a real-world case study with 5x performance improvement.

A comprehensive comparison of sentiment analysis capabilities across Azure Cognitive Text Analytics, AWS Comprehend, and custom fine-tuned models like RoBERTa and Phi2.