
This is the white-paper version of a thing I’ve written about twice from the trenches — the time I graded my parser against itself, and the bake-off where the best model flipped with the layout. Here’s the whole system, start to finish, and the one principle under all of it.
I’m building a healthcare clinic-rollup. That sentence hides a lot of unglamorous work, and one of the least glamorous parts is this: during due diligence on every target, I have to turn a stack of PDF bank statements into a clean ledger of transactions I can actually reason about. Thousands of rows. Deposits, withdrawals, fees, transfers, running balances. Across a dozen different banks, each with its own statement layout, some digital and some scanned crooked on somebody’s office copier in 2021.
This is the kind of task you’d assume is solved. “Just throw an AI OCR model at it.” I assumed that too. Then I watched a model read a statement, drop one $4,812.00 withdrawal silently, and hand me back a ledger that looked perfect and was wrong by almost five thousand dollars. Nothing flagged it. No error. Just a missing row in a sea of correct rows.
That’s the whole problem, and it’s worth being precise about why it’s fatal here specifically.
The problem: “mostly works” is a synonym for “silently wrong”
Modern document-AI models are genuinely impressive. The best of them score in the high 90s on public benchmarks. On a real bank statement, they’ll get 95%, 99%, sometimes more of the amounts exactly right.
For most tasks, 99% is a great grade. For financial due diligence, 99% is not a pass — it’s a refuse.
Think about what 99% means on a 200-row statement: you’re silently wrong on about two transactions. You don’t know which two. The output looks complete and confident. If you’re summarizing an article, a 1% error is a typo. If you’re deciding whether to buy a business — sizing its real cash flow, spotting whether the owner is running personal expenses through the company account — a 1% silent error in which transactions exist is a landmine. And it’s invisible, because the failure mode of these models isn’t “throws an error.” It’s “returns a beautiful, plausible, subtly incomplete answer.”
I ran a bake-off across a half-dozen leading models — finance-tuned OCR models, general vision-language models, and pipeline-style document parsers — measuring one brutally simple metric: exact-to-the-cent transaction recall. Did every single amount on the printed page show up, correct, in the output? Not “looks good.” Not a fuzzy match. To the cent.
The spread was ugly:
- One well-regarded general model captured as few as 0% and at most ~66% of the amounts exactly, depending on the statement — and no single configuration worked across banks. One layout it nailed; the next it collapsed on entirely.
- A strong document pipeline parser (layout + OCR) read clean layouts well but silently dropped rows on others. Its standalone score looks high on a loose “recall” metric — but a naive “grab every number on the page” baseline scores ~99% on that same loose metric, so the number is meaningless. On the strict exact-to-the-cent test that actually matters, it certified far fewer statements. (That gap is exactly why I stopped trusting recall percentages — the full bake-off has the receipts.)
- The best finance-tuned model held in the mid-90s on the layouts that wrecked everyone else.
Six different models. Not one of them won across all the layouts. That was the first real insight, and it killed the naive plan. There is no “just use the best model.” The best model is layout-dependent, and you don’t always know the layout in advance.
The insight: don’t trust the model — trust the document’s own arithmetic
Here’s the move that turned this from a research curiosity into a production system.
A bank statement is not just a list of transactions. It’s a list of transactions plus a printed proof of its own correctness. Every statement tells you the opening balance, the closing balance, and usually the total deposits and total withdrawals. That’s a checksum the bank already computed for you.
So the question stops being “did the model read this perfectly?” — which you can never verify without re-reading it yourself — and becomes “do the transactions the model extracted reconcile to the totals the bank printed?”
Opening balance, plus every deposit, minus every withdrawal, should equal the closing balance. To the cent. If it does, the extraction is trustworthy — not because I trust the model, but because the document’s own arithmetic vouches for it. If it doesn’t, the extraction is refused. It doesn’t get silently shipped with a 99% asterisk. It gets kicked to a human, with the discrepancy named.
I started calling this reconcile-or-refuse. It’s a small idea with a big consequence: it converts a probabilistic model into a system with a deterministic trust boundary. The model can be as good or as flaky as it wants. The gate only lets through extractions that prove themselves against numbers no model produced.
This is also the honest answer to the benchmark-score arms race. A leaderboard number tells you a model’s average accuracy on someone else’s documents. It tells you nothing about which of your transactions it dropped. The reconcile gate doesn’t care about the average. It cares about this statement, right now, tying out.
The bake-off result that surprised me: two complementary models beat the whole zoo
Once you have a reconcile gate, the goal changes. You no longer need a model that’s perfect. You need a set of models such that, for any given statement, at least one of them captures every transaction — and then the gate sorts out the truth.
This reframes “which model is best?” as “which combination gives the gate something to certify?” So I tested combinations: unions, intersections, majority votes, layout-routers. The result was clean and a little humbling.
The best policy was a union of just two models, plus the reconcile gate. Take everything model A extracted, take everything model B extracted, merge them, and let the gate filter. That combination certified 20 of 21 validated statements across eight different bank formats. The best single model managed only 13 of those 21 — a third of the way short of the pair.
Two more findings fell out, and they’re the genuinely transferable lessons:
1. The third model adds nothing. Going from one model to two took me from roughly 5-in-12 to roughly 11-in-12 cells passing on the hard-layout subset. Adding a third model: zero improvement. The union-size curve plateaus hard at two. This isn’t intuition, it’s the data — two is the sweet spot, and the instinct to throw the whole model zoo at the problem is wasted compute.
2. Pair complementary models, not the top two. This is the counterintuitive part. My two best models were both vision-language models, and they failed the same way on the same statements — they’re correlated. Unioning two correlated models barely helps, because where one drops a transaction, so does the other.
The winning pair was a vision-language model and a document pipeline parser (a layout-plus-OCR pipeline — not the plain text-layer parser from tier 1 below; a different tool, for scanned pages). They have opposite failure modes. The VLM over-extracts: on the layouts that confuse it, it dumps the running-balance column as extra rows. The pipeline parser under-extracts: it plays it safe and silently skips rows it’s unsure about. On its own, each is unusable — and the under-extractor is the more dangerous of the two (a dropped row, as we’ll see, is unrecoverable). But union them: where the pipeline parser silently drops a row, the VLM almost always caught it; where the VLM hallucinates a balance as a transaction, the gate strikes it out against the printed totals. Their mistakes don’t overlap, so between the two of them every real transaction gets seen by someone, and the gate cleans up the VLM’s excess. Opposite errors cancel. Correlated errors compound.
And here’s the asymmetry that makes this work at all: over-extraction is gate-recoverable; under-extraction is gate-fatal. If a model gives you too many rows, the reconcile gate can identify and filter the spurious ones, because the printed totals tell it exactly how much real money moved. But if a model gives you too few rows — if it silently dropped a transaction — the gate can flag that the statement won’t reconcile, but it cannot conjure the missing transaction back. You can subtract noise. You cannot add back a number nobody captured. That’s why recall, not precision, is the survival metric, and why you build your model set to guarantee someone saw every row.
Why the layout breaks the models — the inline running-balance trap
The single layout that broke every general model is worth dwelling on, because it explains the whole phenomenon.
Some banks print a transaction register with a running balance on every line — date, description, amount, and then the account balance after that transaction, inline, down the right edge of the page. It’s the most human-readable format. It is also catnip for a model that has learned “numbers in a financial table are important, transcribe all of them.”
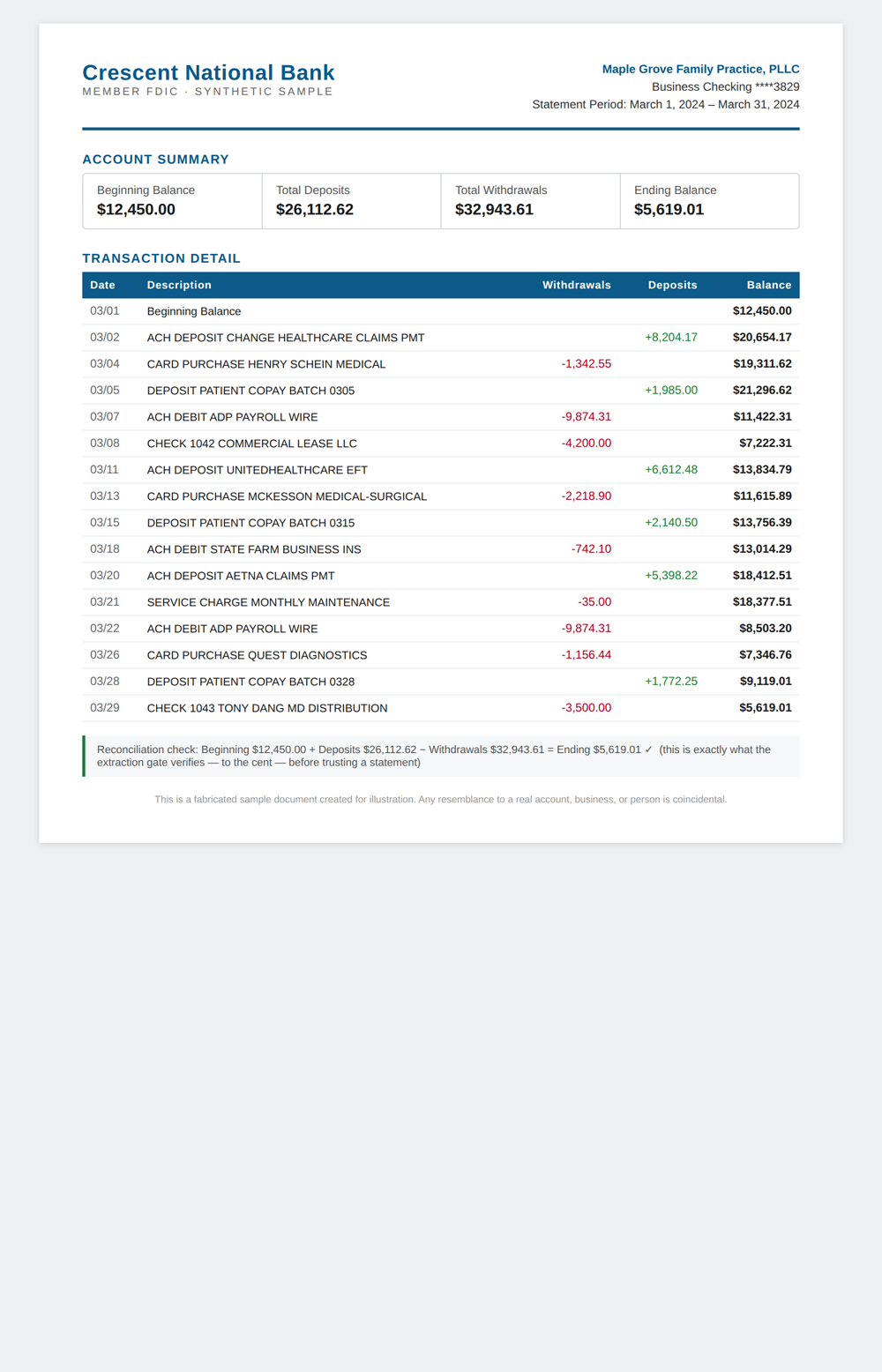
General vision-language models see that right-hand running-balance column and faithfully dump it into their output as if those balances were transactions. Now your extracted ledger is polluted with the running balance after every line — numbers that are real, printed right there on the page, but are not transactions. Every general model I tested collapsed on this layout, scoring in the 60s. The only model that held was one specifically fine-tuned on financial documents — it had learned that the balance column is structure, not data.
That’s the lesson in miniature: a model’s benchmark score is its performance on the layouts it was trained on. Your documents are the layouts it wasn’t. The reconcile gate is what protects you in that gap, because it judges the output by the document’s arithmetic, not the model’s confidence.
The production system: one door, layered, refuse-by-default
All of this collapses into a system with a single front door — you hand it a PDF, it auto-detects what kind of document it is — and a layered pipeline behind it, cheapest and most reliable first:
-
Digital PDF? Parse the text layer directly. If the statement is a real digital PDF (not a scan), the transactions are right there as selectable text. A deterministic parser pulls them in milliseconds, on CPU, with zero model involved and zero hallucination — and reconciles. No GPU should ever be spent OCR-ing a document whose text you can already read. This handles the majority of statements essentially for free.
-
Scanned or image-only? Run the two-model union, then the gate. This is the expensive tier — actual vision models on a GPU — so it only runs when tier 1 can’t. Run the complementary pair, union the results, and let the reconcile gate certify or refuse.
-
Won’t reconcile? Refuse — route to a human, with the discrepancy named. This is the load-bearing rule and the entire point. Anything that does not tie out to the printed totals does not get shipped as data. It gets surfaced as “this statement does not reconcile; here is the gap,” and a person looks at it. The system’s job isn’t to always have an answer. It’s to never hand you a wrong answer dressed up as a right one.
A surprising amount of this design is about what the system refuses to do. It refuses to OCR a document it can read as text. It refuses to trust a model it can check against arithmetic. It refuses to ship a number that doesn’t tie out. The reliability doesn’t come from a smarter model — it comes from a pipeline that knows the difference between “I have an answer” and “I have a verified answer,” and only ever gives you the second one.
The takeaway, beyond bank statements
The specific artifact here is a bank-statement extractor. The principle generalizes to any task where an AI produces structured data that downstream decisions depend on.
Models are probabilistic. Decisions need to be deterministic. You bridge that gap not by waiting for a perfect model — there isn’t one, and the benchmark leaderboard will keep lying to you about which one is best for your inputs — but by finding the checksum already latent in your data and refusing to ship anything that fails it. Bank statements have printed totals. Invoices have line-items that sum to a stated total. Lab results have reference ranges. Find the document’s own proof of correctness, and make your system reconcile to it or refuse.
The model gives you text. The gate gives you data you can bet on. For anything involving money, that distinction is the whole game.
Related: I Said My Parser Was 100% Accurate. I Was Grading It Against Itself. · The Best One Flipped With the Layout. The figure above is fully synthetic; the production benchmark ran on real financial records that aren’t published.