A registration clerk at one of our clinics squinted at the screen, deleted the garbled member ID the system had pulled from an insurance card photo, and typed it in by hand. Fourth card that morning. She’d been doing this for months — the OCR (optical character recognition, software that reads text from images) was “mostly” right, which meant it was also partly wrong often enough that staff had memorized which fields to double-check first.
I had shipped that OCR system.
Our single-model approach — minicpm-v:8b, a compact AI model that can look at images and read text from them, running through a self-hosted CardOCR API — was hitting about 56% exact match accuracy across 10 key fields on a 27-card test set. Nearly half the fields needed manual correction. Staff were spending almost as much time fixing OCR output as they would have spent typing it manually.
The fix wasn’t a better model. It was routing each field to whichever model was already better at it.
Different Models Fail Differently
I ran a systematic comparison of two open-source vision models — AI systems that can read text from images — against our ground truth dataset of manually verified card data. The two contenders:
- minicpm-v:8b — A compact multimodal model (processes both images and text), great at short, structured fields like member IDs and group numbers.
- llama3.2-vision:11b — Meta’s larger vision model, with a bigger language head (the part that turns what it sees into words), better at reading variable-length descriptive text.
I’d initially picked minicpm-v because it was faster and its overall accuracy number looked better. That was the wrong way to look at it. Aggregate scores hide everything that matters.
The field-level breakdown told the real story.
the mechanism — why field routing works and how to build it give me the detail
Why complementary failure modes are the key insight. minicpm-v:8b is a compact multimodal model optimized for short, structured alphanumeric strings — exactly what member IDs and group numbers are. llama3.2-vision:11b has a larger language head that handles variable-length descriptive text better, which explains why it wins on payer names and pharmacy codes (RxBIN/RxPCN/RxGrp are more like short prose tokens than fixed-width IDs). The ensemble exploits this split structurally, not by averaging scores.
Running both models via Ollama (ollama pull llama3.2-vision:11b) means you get the GPU batching and REST interface for free — no custom serving infra needed. Both models are dispatched in parallel with Python’s ThreadPoolExecutor, so total latency is max(t_a, t_b), not t_a + t_b.
The routing table is just a dict — build yours by running each model against a labeled sample set, computing per-field exact-match rate, and writing the winner into a config:
FIELD_ROUTER = {
"member_id": "cardocr",
"group_number": "cardocr",
"subscriber_name": "cardocr",
"payer_id": "cardocr",
"plan_name": "cardocr",
"copay": "cardocr",
"payer_name": "ollama",
"rx_bin": "ollama",
"rx_pcn": "ollama",
"rx_grp": "ollama",
}
def merge(cardocr_result: dict, ollama_result: dict) -> dict:
return {
field: (cardocr_result if src == "cardocr" else ollama_result).get(field)
for field, src in FIELD_ROUTER.items()
}Concrete takeaway: before pulling a bigger model, label 20-30 real samples per field and compute per-field accuracy for each model you already have. You may find the gains you need are free — already sitting in a model you’re not routing to.
| Field | minicpm-v:8b | llama3.2-vision:11b | Routed to |
|---|---|---|---|
| member_id | 74.1% | 66.7% | minicpm-v |
| group_number | 63.0% | 51.9% | minicpm-v |
| subscriber_name | 81.5% | 77.8% | minicpm-v |
| payer_id | 11.1% | 7.4% | minicpm-v |
| plan_name | 29.6% | 22.2% | minicpm-v |
| copay | 59.3% | 48.1% | minicpm-v |
| payer_name | 51.9% | 59.3% | llama3.2-vision |
| rx_bin | 70.4% | 74.1% | llama3.2-vision |
| rx_pcn | 48.1% | 59.3% | llama3.2-vision |
| rx_grp | 70.4% | 77.8% | llama3.2-vision |
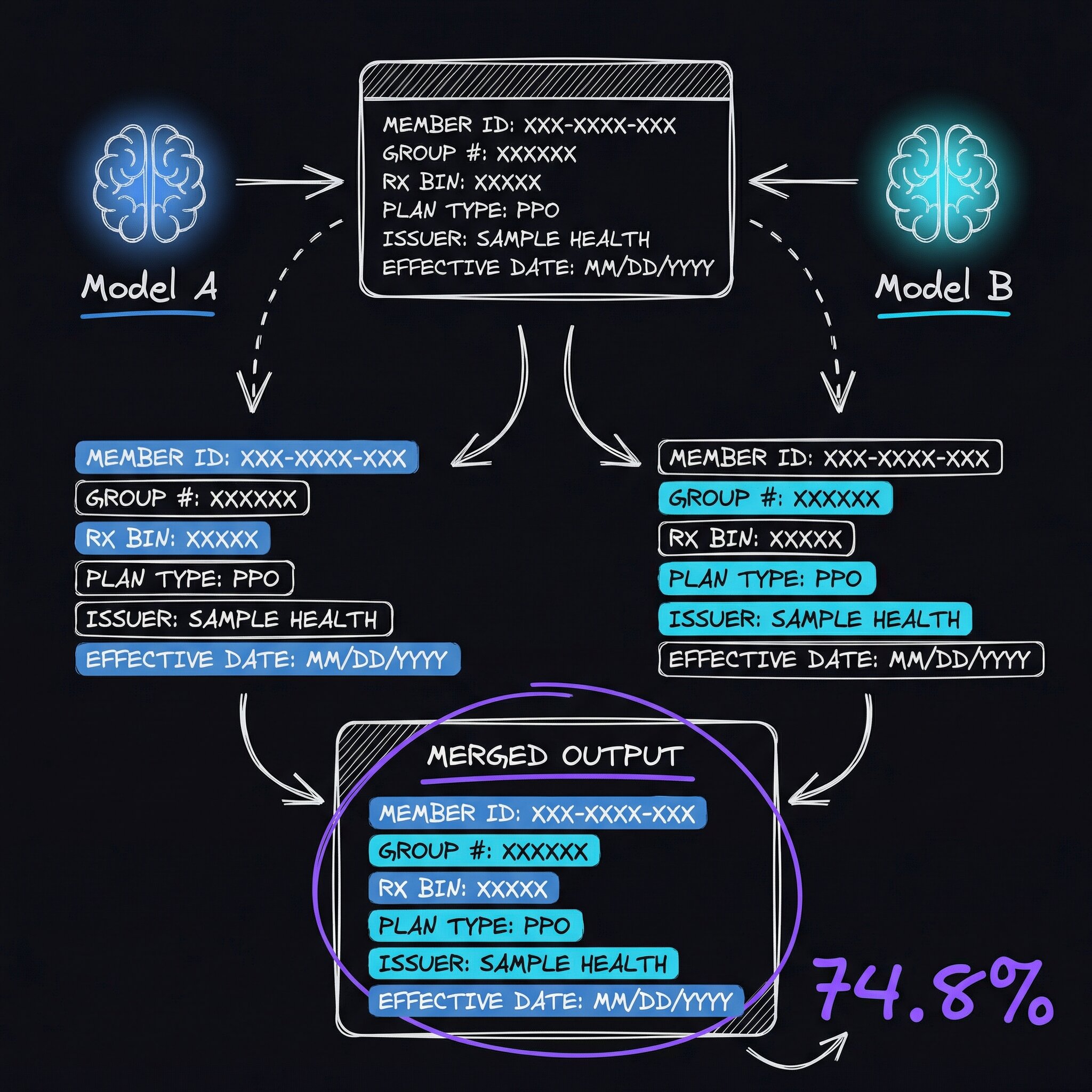
minicpm-v dominates on structured ID fields — member IDs, group numbers, subscriber names. llama3.2-vision wins on the pharmacy triplet (RxBIN, RxPCN, RxGrp — the codes that identify which pharmacy benefit plan covers the patient) and payer names. Neither model is great at everything. But together they cover each other’s blind spots.
If I’d only compared overall accuracy, I would have picked minicpm-v (56% vs 53%) and completely missed that llama3.2-vision was significantly better on 4 out of 10 fields. I almost did exactly that.
Routing Fields, Not Picking a Winner
The ensemble approach is dead simple: instead of choosing one model, send the card image to both, then route each field to whichever model is best at extracting it.
Insurance Card Image
│
├──→ CardOCR (minicpm-v:8b) ──→ member_id, group_number,
│ subscriber_name, payer_id,
│ plan_name, copay
│
└──→ Ollama (llama3.2-vision) ──→ payer_name, rx_bin,
rx_pcn, rx_grp
│
└──→ Merge by field routing tableBoth models run in parallel — a single model already takes 3-5 seconds, so running two concurrently costs almost nothing extra. Total latency is roughly 5-6 seconds: the slower of the two, not the sum of both.
This is the cheap part of ensembles people overlook. The latency cost of two models run concurrently is max(model_a, model_b), not model_a + model_b. For an insurance card upload that already takes a few seconds, nobody notices the difference.
What Actually Improved
The ensemble moved the needle — not dramatically, but meaningfully:
| Metric | Single Model | Ensemble | Improvement |
|---|---|---|---|
| Exact match | 55.9% | 59.3% | +3.4 points |
| Fuzzy match | 72.9% | 74.8% | +1.9 points |
“Exact match” means the extracted text matched the ground truth character-for-character. “Fuzzy match” gives partial credit for close-but-not-perfect extractions — a member ID like “WXD-1234” vs “WXD1234” counts as fuzzy-correct. A 3.4-point improvement in exact match means fewer fields for staff to correct per card. On a busy day with 50+ patient check-ins, that adds up.
Is 59.3% good enough? No. It’s better than 55.9%, and there’s plenty of headroom left. But the shape of the improvement matters more than the absolute number — it came from routing, not from a bigger model. That’s the pattern worth replicating.
How It Runs in Production
The implementation is straightforward. The OCR service dispatches both models using a Python thread pool (a mechanism that runs multiple tasks concurrently on the same machine), then merges results through the routing table:
# Both models run concurrently
with ThreadPoolExecutor(max_workers=2) as executor:
cardocr_future = executor.submit(call_cardocr, image)
ollama_future = executor.submit(call_ollama, image)Four design decisions that kept this from becoming a maintenance headache:
-
Graceful degradation — If Ollama fails or times out, the system falls back to CardOCR-only results. If CardOCR fails but Ollama succeeds, we use what we have. The ensemble path never returns worse results than the original single-model path.
-
Feature flag —
OCR_ENSEMBLE_ENABLED=trueis a toggle switch that turns the ensemble on or off without redeploying code. Set it to false and behavior is identical to the original single-model path. This meant we could ship the code dark, flip the flag in one clinic first, and roll back instantly if something broke. -
JSON repair — AI models don’t always return clean JSON (the structured data format programs use to exchange information). Ollama occasionally wraps its output in markdown code blocks, truncates mid-response, or produces mismatched braces. The integration layer strips markdown formatting, repairs truncated JSON where possible, and falls back to regex extraction (pattern-matching the text directly) as a last resort.
-
No caller changes — All five integration points (patient registration, the admin EHR system, the re-run endpoint, and two others) call the same
extract_insurance_card()method. The ensemble is entirely internal to that method. Zero downstream code changed.
What I Learned
You don’t need a better model — you need the right model for each field. Two 8-11B parameter models running on a single GPU, each mediocre on their own, outperform either one alone when you route fields intelligently. Before upgrading to a bigger model, check if your current models have complementary strengths.
Field-level evaluation matters more than aggregate scores. Looking only at overall accuracy would have buried the fact that llama3.2-vision was winning on 4 of 10 fields. The aggregate was a lie.
Parallel execution makes ensembles cheap. The latency cost of running two models is max(model_a, model_b) when you parallelize — not 2×. For an upload that already takes a few seconds, the user doesn’t notice.
The system is live now at our clinics. Next step: expanding the test set and checking whether a third model — or a fine-tuned one trained specifically on insurance cards — can push accuracy past 80%.