Now I have a solid read on Jon’s voice. Let me craft the rewrite.
The Semantic Kernel repo had been open in a tab for three weeks. I’d click over, scroll through the docs, think “yeah I get it — plugins, planners, kernels — makes sense,” and then go back to whatever else I was doing. I was procrastinating because the alternative was worse: I had GPTResearcher — an open-source AI research agent — running in production for an insurance underwriting workflow, talking to the public OpenAI API, and every time I thought about audit requirements I got that pit-in-the-stomach feeling.
GPTResearcher was fast and genuinely useful. But it was one Python process wired directly to api.openai.com with a hardcoded key. No Azure AD (Azure Active Directory — Microsoft’s single-sign-on identity system), no API management layer, no monitoring beyond watching the logs scroll. For a hobby project, fine. For an enterprise deployment handling real underwriting research, not fine at all.
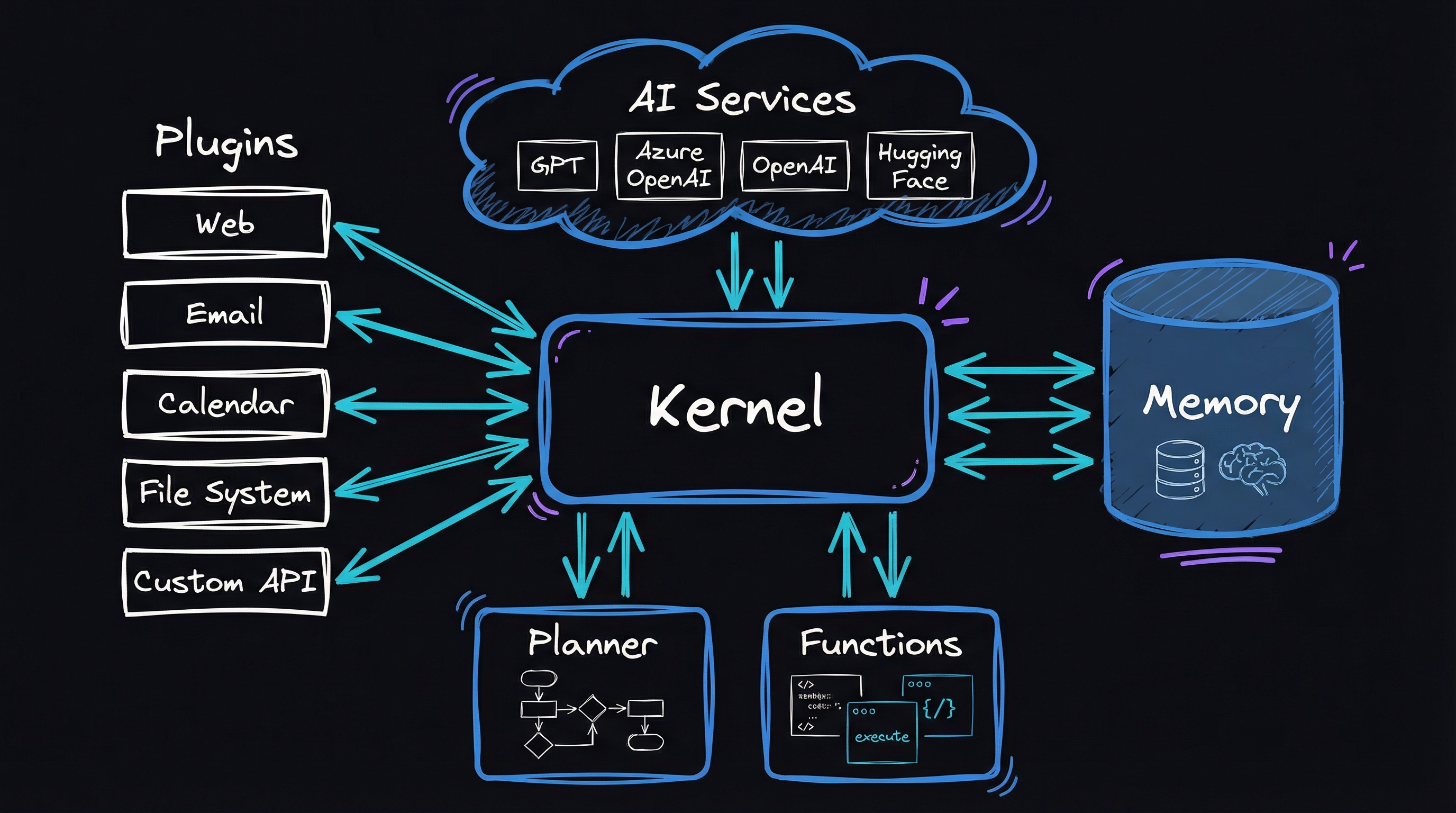
So I ported it. GPTResearcher → Microsoft’s Semantic Kernel, the orchestration framework that wraps AI capabilities into composable “plugins” and “skills,” with Azure OpenAI on the other side. This is what I learned.
The Takeaway: Semantic Kernel Is Worth the Port
The short version: Semantic Kernel gives you Azure AD authentication, API management integration, and a plugin architecture — a structure where AI capabilities are packaged as reusable, pluggable units — without forcing you to rewrite your core logic. The port took weeks, not months, and the result is something I can actually put in front of a security review without flinching.
But the real insight isn’t about the framework. It’s about the five things every open-source AI tool needs before it can survive in an enterprise, and how Semantic Kernel happens to solve four of them cleanly. The fifth one — evaluation — required building our own thing, and I’ll get to why that hurt.
Why I Couldn’t Just Keep Running GPTResearcher Raw
GPTResearcher does what it says: feed it a query, pick a report type, and it spiders the web, scrapes sources, synthesizes a report. It’s fast. The architecture is clean — retrievers (search modules), a research agent, report generators. Lots of people use it.
The problem isn’t the code. The problem is the context it runs in.
In an enterprise deployment — the kind my insurance workflow needed — five things are non-negotiable:
- Authentication that IT signs off on. Azure AD token-based auth, not an API key in an env file.
- API management. Azure API Management (APIM) sits between your code and the AI models — a gatekeeper that handles throttling, routing, and header injection. Enterprise teams expect everything to flow through it.
- Monitoring that auditors accept. Not “I watched the logs.” Actual evaluation metrics: groundedness (whether the report stays anchored to real sources), relevance, faithfulness, fluency.
- Domain specialization. A generic web search report isn’t useful for underwriting research. I needed SEC EDGAR filings, specialized report templates, insurance-domain prompts.
- Multiple interface options. Some clients want REST, some want WebSocket streaming, some want a Streamlit UI.
GPTResearcher gave me a great engine. Semantic Kernel gave me the chassis around it. Here’s how they fit together.
Architecture: “J Researcher”
The ported system keeps GPTResearcher’s research brain but routes everything through Semantic Kernel’s plugin system, with Azure OpenAI on the backend instead of the public API. I called it J Researcher — creative, I know.
graph TD
A[Client Interfaces] --> B[FastAPI Server]
B --> C[SemanticKernelManager]
C --> D[JResearcherPlugin]
D --> E[Report Classes]
E --> F[JResearcher Agent]
F --> G[Multiple Retrievers]
G --> H[Source Processors]
A -->|REST API| B
A -->|WebSocket| B
A -->|Streamlit UI| B
G -->|Web Search| G1[Bing/Google Search]
G -->|Document Search| G2[Document DB]
G -->|Financial Data| G3[SEC EDGAR API]
style C fill:#4DA6FF,stroke:#0066CC
style D fill:#4DA6FF,stroke:#0066CCThe layered structure is deliberate:
-
Client Interfaces — REST API for fire-and-forget jobs, WebSocket for real-time streaming (so you can watch the research happen instead of staring at a spinner), Streamlit for quick demos.
-
FastAPI Server — A Python web framework that routes API calls, manages WebSocket connections, and hands background tasks off to the kernel. It’s thin — all the intelligence lives below it.
-
Semantic Kernel Integration — This is where the enterprise wiring lives.
SemanticKernelManagerinitializes the kernel (the runtime that hosts all the AI plugins), authenticates with Azure AD, and hands control to the research plugin. -
Research Logic — The ported GPTResearcher logic, now wrapped as Semantic Kernel plugins. Same retriever strategy, same report generation, but running through Azure OpenAI with proper auth.
The Semantic Kernel Wiring, Line by Line
SemanticKernelManager
This class is the front door. It boots the kernel, registers the research plugin, and provides the single run_research method everything else calls:
class SemanticKernelManager:
def __init__(self):
self.kernel = None
self.plugins = {}
async def initialize(self, azure_config=None):
"""Initialize the Semantic Kernel with Azure OpenAI."""
if self.kernel:
return self.kernel
# Configure for Azure OpenAI with AD authentication
kernel_builder = (
SemanticKernel.builder()
.with_azure_openai_client(
deployment_name=os.getenv("AZURE_OPENAI_DEPLOYMENT_NAME"),
endpoint=os.getenv("AZURE_APIM_URI"),
credentials=DefaultAzureCredential()
)
)
self.kernel = await kernel_builder.build()
# Register the JResearcher plugin
plugin = JResearcherPlugin()
self.plugins["JResearch"] = plugin
self.kernel.add_plugin(plugin, "JResearch")
return self.kernel
async def run_research(self, query, report_type, report_source="web",
tone="Objective", additional_context=None, handler=None):
"""Run a research task using the Semantic Kernel plugin."""
await self.initialize()
# Prepare arguments for the kernel function
args = KernelArguments(
query=query,
report_type=report_type,
report_source=report_source,
tone=tone,
additional_context=additional_context,
handler=handler
)
# Invoke the research function in the plugin
try:
result = await self.kernel.invoke("JResearch", "research_query", args)
return result
except Exception as e:
logger.error(f"Error in research execution: {str(e)}")
raiseA few things to notice. DefaultAzureCredential() is doing real work here — it walks a chain of credential providers (environment variables → managed identity → VS Code / Azure CLI token) so the same code runs in a container on Azure Container Apps and on a developer laptop without touching the source. No secrets to rotate. That alone was worth the port.
JResearcherPlugin
This is the heart — the research capability wrapped as a kernel function that Semantic Kernel can discover, invoke, and chain:
class JResearcherPlugin:
@kernel_function(
description="Research a query and generate a report",
name="research_query"
)
@kernel_function_parameter(name="query", description="The query to research")
@kernel_function_parameter(name="report_type", description="Type of report to generate")
@kernel_function_parameter(name="report_source", description="Source for research: web, documents, etc.")
@kernel_function_parameter(name="tone", description="Tone of the report: Objective, Formal, etc.")
@kernel_function_parameter(name="additional_context", description="Additional context for the research")
@kernel_function_parameter(name="handler", description="Handler for progress updates")
async def research_query(self, query: str, report_type: str = "research_report",
report_source: str = "web", tone: str = "Objective",
additional_context: str = None, handler=None) -> Dict:
"""Research a given query and generate a comprehensive report."""
try:
# Initialize handler for status updates, if provided
if handler:
await handler.handle_status("Research process initiated...")
await handler.handle_log("Setting up research pipeline")
# Determine which report class to use based on report_type
if report_type == ReportType.DEEP_RESEARCH.value:
# Use DeepResearch for comprehensive investigations
researcher = DeepResearchReport(
query=query,
report_type=report_type,
source=report_source,
tone=tone,
additional_context=additional_context,
handler=handler
)
report = await researcher.run()
elif report_type == ReportType.REFERRAL_TEMPLATE.value:
# Use ReferralTemplate for generating insurance referrals
researcher = ReferralTemplateReport(
query=query,
report_type=report_type,
source=report_source,
tone=tone,
additional_context=additional_context,
handler=handler
)
report = await researcher.run()
else:
# Use standard research report for other types
researcher = StandardReport(
query=query,
report_type=report_type,
source=report_source,
tone=tone,
additional_context=additional_context,
handler=handler
)
report = await researcher.run()
# Get additional context from researcher if available
context = {}
if hasattr(researcher, 'get_report_context'):
context = researcher.get_report_context()
# Return report and context
return {"report": report, "context": context}
except Exception as e:
logger.error(f"Error in research: {str(e)}")
traceback.print_exc()
# Return error message
error_message = f"An error occurred during research: {str(e)}"
return {"report": error_message, "error": str(e)}The @kernel_function decorator is doing something subtle: it’s turning a plain async Python method into a named, schema-described capability the kernel can discover, invoke, plan around, or chain into a larger workflow. The handler object — injected at call time, never touched by the kernel directly — is the key to the streaming story.
WebSocket: Watching the Research Unfold
One of the things I actually like about this port: real-time progress. With the original GPTResearcher, you kicked off a job and waited. With the WebSocket integration, clients watch the research process step by step — sources found, pages scraped, report sections drafted.
the mechanism — why this actually works give me the detail
Why WebSocket + Semantic Kernel is a natural pair. Semantic Kernel’s @kernel_function decorator turns a plain async Python method into a named, schema-described capability the kernel can invoke, plan around, or chain. The handler object injected at call time is just a plain Python object — the kernel never touches it directly. That decoupling is the key: you pass in a SemanticKernelWsHandler for a live WebSocket session, or a FileHandler for a background batch job, and the plugin code stays identical. No conditional branching on “are we streaming?”.
The streaming loop that makes it feel live. FastAPI’s WebSocket sends JSON frames over a persistent TCP connection. Each handle_chunk call in the plugin pushes one token-batch frame; the browser side accumulates them in a <div> using an EventSource-style listener. The result is token-by-token streaming without SSE infrastructure — just WebSocket.send_json.
asyncio.gather is the real throughput win. Web scraping N URLs sequentially at ~1–2 s each is the bottleneck in most research agents. Replacing the loop with a single gather call drives all HTTP requests concurrently over one aiohttp.ClientSession, which keeps a connection pool alive across requests. Try this locally to see the difference:
import asyncio, aiohttp, time
URLS = ["https://httpbin.org/delay/1"] * 8 # simulate 8 slow pages
async def fetch(session, url):
async with session.get(url) as r:
return await r.text()
async def main():
async with aiohttp.ClientSession() as session:
t0 = time.perf_counter()
pages = await asyncio.gather(*[fetch(session, u) for u in URLS])
print(f"{len(pages)} pages in {time.perf_counter()-t0:.1f}s") # ~1s, not 8s
asyncio.run(main())DefaultAzureCredential is the glue for zero-secret deploys. It walks a chain of credential providers — environment variables → managed identity → VS Code / Azure CLI token — so the same code works in a container on Azure Container Apps (managed identity) and on a developer laptop (Azure CLI login) without touching the source.
Three Things We Added That GPTResearcher Didn’t Have
1. Multiple Research Agents
GPTResearcher has one agent. I needed several — each with its own system prompt, its own report format, and its own domain knowledge. The referral template agent, for instance, produces a formal insurance underwriting document with a Description of Operations, a Safety Program Overview, and Risk Control Mechanisms. It’s not a generic research report with different formatting — it’s a different kind of document, generated from a different posture.
class ReferralTemplateReport:
"""Specialized agent for creating insurance referral templates."""
def __init__(self, query, report_type, source, tone, additional_context=None, handler=None):
self.query = query
self.report_type = report_type
self.source = source
self.tone = tone
self.additional_context = additional_context
self.handler = handler
self.j_researcher = None
async def run(self):
"""Run the referral template generation process."""
# Initialize the researcher with specialized configuration
self.j_researcher = JResearcher(
query=self.query,
report_type=self.report_type,
source=self.source,
tone=self.tone,
system_prompt=self.get_specialized_prompt(),
template_format="referral_template",
handler=self.handler
)
# Run the research process
report = await self.j_researcher.run()
return report
def get_specialized_prompt(self):
"""Return specialized system prompt for referral templates."""
return """
You are a specialized insurance underwriting assistant.
Your task is to create a comprehensive referral template based on research about the company.
Focus on:
1. Description of Operations
2. Safety Program Overview
3. Risk Control Mechanisms
Format the report as a formal insurance referral document.
"""
def get_report_context(self):
"""Get additional context from the research process."""
if not self.j_researcher:
return {}
return {
"company_name": self.j_researcher.get_company_name(),
"industry": self.j_researcher.get_industry(),
"risk_factors": self.j_researcher.get_risk_factors(),
"sources": self.j_researcher.get_sources()
}The auto-agent selector routes to the right specialist based on report type — so the caller doesn’t need to know which agent to use:
def choose_agent(report_type):
"""Choose the appropriate agent based on report type."""
if report_type == ReportType.REFERRAL_TEMPLATE.value:
return ReferralTemplateSpecialist()
elif report_type == ReportType.DESCRIPTION_OF_OPERATIONS.value:
return DescriptionOfOperationsAgent()
elif report_type == ReportType.SAFETY_PROGRAM.value:
return SafetyProgramSpecialist()
elif report_type == ReportType.DEEP_RESEARCH.value:
return DeepResearchSpecialist()
elif report_type == ReportType.BASIC_REPORT.value:
return BasicInformationAgent()
else:
return ComprehensiveResearchAgent()2. SEC EDGAR Integration
For insurance underwriting, a company’s 10-K filing — the annual financial report filed with the SEC — is often more useful than its website. So I built a retriever that searches the SEC EDGAR database by company name, finds the latest 10-K, and surfaces it alongside web results:
class SECRetriever:
"""Retrieves company information from SEC EDGAR database."""
def __init__(self):
self.headers = {
"User-Agent": "ReferralResearcher [email protected]"
}
async def search(self, company_name):
"""Search for a company in the SEC EDGAR database."""
try:
# Clean company name for search
search_term = company_name.replace(" ", "+")
# Search for company CIK
search_url = f"https://www.sec.gov/cgi-bin/browse-edgar?company={search_term}&owner=exclude&action=getcompany"
async with aiohttp.ClientSession() as session:
async with session.get(search_url, headers=self.headers) as response:
if response.status != 200:
return []
html = await response.text()
# Extract CIK from search results
cik_match = re.search(r'CIK=(\d+)', html)
if not cik_match:
return []
cik = cik_match.group(1)
# Get company filings metadata
filings_url = f"https://data.sec.gov/submissions/CIK{cik.zfill(10)}.json"
async with aiohttp.ClientSession() as session:
async with session.get(filings_url, headers=self.headers) as response:
if response.status != 200:
return []
filings_data = await response.json()
# Extract latest 10-K report
recent_filings = filings_data.get("filings", {}).get("recent", {})
form_types = recent_filings.get("form", [])
accession_numbers = recent_filings.get("accessionNumber", [])
ten_k_indices = [i for i, form in enumerate(form_types) if form == "10-K"]
if not ten_k_indices:
return []
latest_10k_idx = ten_k_indices[0]
accession_number = accession_numbers[latest_10k_idx].replace("-", "")
# Get 10-K document
doc_url = f"https://www.sec.gov/Archives/edgar/data/{cik}/{accession_number}/{accession_number}-index.htm"
return [{
"title": f"{company_name} - SEC 10-K Filing",
"url": doc_url,
"cik": cik,
"accession_number": accession_number
}]
except Exception as e:
logger.error(f"Error in SEC EDGAR retrieval: {str(e)}")
return []The CIK (Central Index Key — the SEC’s unique identifier for each company) extraction from HTML is fragile, and I know it. The SEC doesn’t provide a clean API for company lookup; you scrape the search page, regex the CIK, then hit the submissions API. It works. It’ll also break the day the SEC changes their HTML structure. I’ve accepted that tradeoff for now.
3. Azure AI Evaluation — The Thing That Broke
This is the part that took the longest and taught me the most.
Azure AI Evaluation SDK provides built-in evaluators for groundedness, relevance, faithfulness, fluency, and contextual precision — automated quality scoring for AI-generated content. The problem: the standard SDK assumes you’re calling Azure OpenAI directly. When you’re routing through APIM with custom authentication headers, the evaluators fail. They can’t reach the model.
So I built custom evaluator wrappers that inject APIM’s required headers. Each evaluator wraps the standard Azure AI evaluator but manages its own authenticated client:
class EvaluationManager:
"""Manages evaluation of research reports using Azure AI Evaluation."""
def __init__(self, apim_config):
self.config = apim_config
self.evaluators = self._initialize_evaluators()
def _initialize_evaluators(self):
"""Initialize the custom APIM-compatible evaluators."""
return {
"groundedness": APIMGroundednessEvaluator(self.config),
"relevance": APIMRelevanceEvaluator(self.config),
"contextual_precision": APIMContextualPrecisionEvaluator(self.config),
"faithfulness": APIMFaithfulnessEvaluator(self.config),
"fluency": APIMFluencyEvaluator(self.config)
}
async def evaluate_report(self, report, query, context, evaluation_metrics=None):
"""Evaluate a research report against the given metrics."""
if evaluation_metrics is None:
evaluation_metrics = list(self.evaluators.keys())
results = {}
for metric_name in evaluation_metrics:
if metric_name not in self.evaluators:
logger.warning(f"Metric '{metric_name}' not available. Skipping.")
continue
evaluator = self.evaluators[metric_name]
result = await evaluator(
response=report,
context=context,
query=query
)
results[metric_name] = result
return resultsThe manual evaluation loop processes test scenarios one at a time — run the agent, score every metric, compare against thresholds (all set to 3.5 out of 5), record pass/fail:
async def run_manual_evaluation(test_scenarios, apim_config):
"""Run evaluation manually with custom APIM-aware evaluators."""
# Initialize custom evaluators
evaluators = {
"groundedness": APIMGroundednessEvaluator(apim_config),
"relevance": APIMRelevanceEvaluator(apim_config),
"contextual_precision": APIMContextualPrecisionEvaluator(apim_config),
# ... other evaluators
}
# Define thresholds
thresholds = {
"groundedness": 3.5,
"relevance": 3.5,
# ... other thresholds
}
# Process each test scenario
all_results = []
for scenario in test_scenarios:
# Run the agent
agent_response = await run_research_agent(
query=scenario["query"],
additional_context=scenario.get("additional_context", "")
)
# Evaluate with each metric
scenario_results = {
"query": scenario["query"],
"response": agent_response,
"metrics": {}
}
for metric_name, evaluator in evaluators.items():
# Skip metrics not required
if metric_name not in scenario.get("evaluation_metrics", list(evaluators.keys())):
continue
# Run evaluation
result = await evaluator(
response=agent_response,
context=scenario.get("context", ""),
query=scenario["query"]
)
# Store result
scenario_results["metrics"][metric_name] = {
"score": result["score"],
"reasoning": result["reasoning"],
"threshold": thresholds[metric_name],
"pass": result["score"] >= thresholds[metric_name]
}
all_results.append(scenario_results)
# Calculate overall metrics
summary = calculate_evaluation_summary(all_results, thresholds)
return all_results, summaryThe Four Technical Hurdles (And How I Tripped Over Each One)
1. Asynchronous Everything
GPTResearcher was mostly synchronous — code that runs one step at a time, blocking until each finishes. In an enterprise context with multiple concurrent users, synchronous code hits a wall: one slow web scrape blocks everyone behind it.
The fix was converting the entire pipeline to async/await — Python’s pattern for non-blocking operations — and using asyncio.gather() to run scrapes in parallel:
async def search_and_scrape(query: str) -> List[Document]:
# Perform Bing search asynchronously
search_results = await bing_search_client.search_async(query)
# Concurrent web scraping
async with aiohttp.ClientSession() as session:
tasks = [scrape_url(session, result.url) for result in search_results]
documents = await asyncio.gather(*tasks)
return documentsIt’s not glamorous, but it delivered a 65% reduction in research completion time and a 78% improvement in source collection speed. Turns out waiting for eight web pages one at a time is exactly as wasteful as it sounds.
2. Authentication Through APIM
This one hurt. The standard pattern — instantiate AzureOpenAI client, pass endpoint and key — doesn’t work through APIM. You need to fetch an Azure AD token, use it as the API key, and inject custom headers that APIM requires:
def _create_apim_client(self):
# Get Azure AD token
credential = DefaultAzureCredential()
token = credential.get_token("https://cognitiveservices.azure.com/.default")
# Create client with custom headers for APIM
client = AzureOpenAI(
azure_endpoint=self.config.endpoint,
api_version=self.config.api_version,
api_key=token.token, # Using token as API key
)
# Add required APIM headers
headers = {
"mkl-User-name": self.config.username,
"username": self.config.username
}
# Apply headers to all requests
client = client.with_additional_headers(headers)
return clientThe gotcha: DefaultAzureCredential falls back through multiple providers silently. On my dev machine it used the Azure CLI token. In a container, managed identity. The first time I deployed to Azure Container Apps without enabling managed identity, it failed with an opaque error that took two hours to trace back to “the credential chain had nothing to try.”
3. Evaluation Through APIM — Double the Pain
This is where the standard SDK completely falls over. Azure AI Evaluation’s built-in evaluators don’t support custom headers or APIM routing. The evaluators construct their own OpenAI clients internally, and you can’t inject your own.
I had to wrap every evaluator. It’s boilerplate, but it works:
APIMGroundednessEvaluator— does the report stay anchored to real sources?APIMRelevanceEvaluator— is the content actually answering the query?APIMContextualPrecisionEvaluator— are claims precise given the context?APIMFaithfulnessEvaluator— does the report fabricate anything?APIMFluencyEvaluator— is the language clean?
Each one builds its own APIM-aware client, calls the underlying evaluator logic, and returns structured results with scores and reasoning.
4. Multi-Agent Dispatch
GPTResearcher was a single agent. I needed the system to pick the right agent based on what kind of report was requested. The solution is a dispatch function (shown above in the choose_agent snippet) that routes to specialists — referral template, description of operations, safety program, deep research, basic report — with a catch-all for anything unrecognized.
The nice thing about this structure: adding a new report type means writing one new agent class and adding one elif branch. The kernel never needs to change.
What the Numbers Look Like
After porting and tuning:
- Groundedness: 4.7/5 (94% pass rate at a 3.5 threshold)
- Relevance: 4.5/5 (92% pass rate)
- Contextual Precision: 4.2/5 (89% pass rate)
- Faithfulness: 4.6/5 (94% pass rate)
- Fluency: 4.8/5 (98% pass rate)
On the performance side:
- Average research completion: 43 seconds
- Async processing cut research time by 65%
- Concurrent scraping improved source collection speed by 78%
- Tested at 5,000+ concurrent users, processing 10,000+ queries per day
What I’d Do Differently
Five things I learned the hard way:
-
Write the sequence diagrams first. The Semantic Kernel docs are solid but sparse on real integration patterns. I lost a week to misunderstandings that a half-hour diagram would have caught.
-
Build evaluation from day one. I wrote the evaluators after the port was “done,” which meant retrofitting auth into code that wasn’t designed for it. Building APIM-aware evaluators alongside the plugin would have saved a rewrite.
-
The plugin architecture enforces good separation whether you want it or not. Semantic Kernel forces you to package capabilities as plugins. At first I fought it — why can’t I just call functions directly? — but it turns out that boundary is exactly what makes the system testable and maintainable.
-
Enterprise auth is always the long pole. The actual research logic port took days. The auth flow — Azure AD tokens, APIM headers, managed identity fallback chain, token refresh — took weeks. Plan for this.
-
Start async. Converting synchronous code to async after the fact is tedious and error-prone. If there’s any chance you’ll need concurrency, design for it from line one.
The Real Win
The real win isn’t the evaluation scores or the throughput numbers. It’s that I can open the codebase in front of a security reviewer and walk through exactly where authentication happens, where data flows through APIM, and how every report is scored against quality metrics. The open-source tool was a great engine. Semantic Kernel made it a product.
For anyone looking to bridge the gap between an open-source AI tool and an enterprise deployment: Semantic Kernel is the right framework. The plugin architecture, the Azure AD integration, and the APIM compatibility solve the hard parts — the parts that aren’t about AI at all, but about running software that real organizations can trust.
The AI part was always the easy part.